

Nvidia анонсировала три новые видеокарты GeForce RTX на Gamescom 2018, GeForce RTX 2080, GeForce RTX 2080 Ti и GeForce RTX 2070. У нас также есть полные обзоры GeForce RTX 2080 Ti Founders Edition и GeForce RTX 2080 Founders Edition. Мы рассмотрели все детали того, что вам нужно знать о каждом графическом процессоре в этих статьях, но для тех, кто хочет получить техническую поддержку, это будет подробное рассмотрение архитектуры Nvidia Turing.
В архитектуре Turing есть масса новых технологий, в том числе оборудования для трассировки лучей, и Nvidia справедливо называет это крупнейшим улучшением поколения своих графических процессоров за последние десять лет, возможно, когда-либо. Если спецификации для Тьюринга не кажутся чем-то особенным, то есть все те же старые вещи с какой-то причудливой трассировкой лучей и глубоким маркетинговым обучением, то гораздо больше, чем бумажные спецификации. Если вы хотите узнать обо всех самых глубоких и темных секретах Тьюринга, вы попали по адресу.
Последней архитектурой GeForce от Nvidia была Pascal, которая использовала все, от лучших видеокарт высшего уровня, таких как GeForce GTX 1080 и GeForce GTX 1080 Ti, до начального уровня GeForce GTX 1050 и GeForce GT 1030. В прошлом году Nvidia выпустила свою новую архитектуру Volta, добавление ядер Tensor и памяти HBM2 к изображению, но единственной картой pro-sumer для использования Volta является Titan V, монстр за $ 2999. Volta GV100, очевидно, останется в сферах суперкомпьютеров и глубокого обучения, потому что новая архитектура Тьюринга, кажется, превосходит его практически во всех значимых отношениях. Если вы только что разорились на Titan V, это плохая новость, но для геймеров, которые тяготеют к новым видеокартам, ваше терпение (и здравый смысл) окупились.

Полная спецификация архитектуры Тьюринга
Было множество спекуляций и, да, явно ошибочных предположений относительно того, что будет содержать архитектура Тьюринга. До первоначального раскрытия на SIGGRAPH 2018 каждая предполагаемая утечка была поддельной. Высказывание образованных предположений о будущих архитектурах — давняя традиция в Интернете, но такие предположения неизбежно должны быть ошибочными. Ранее мы рассмотрели многие детали архитектуры Тьюринга от Nvidia, но сегодня мы наконец-то можем снять все и перейти к мелким деталям.
Я включаю в следующую таблицу как «полные» чипы Тьюринга, так и варианты GeForce RTX Founders Edition, а также эквиваленты предыдущего поколения Pascal. Выпуски Founders Edition 20-й серии имеют тактовую частоту с повышением частоты на 90 МГц, что ставит их в тот же диапазон, что и модели с заводским разгоном. Вот полные спецификации Тьюринга, включая размер кристалла и количество транзисторов для меньших ядер Тьюринга:
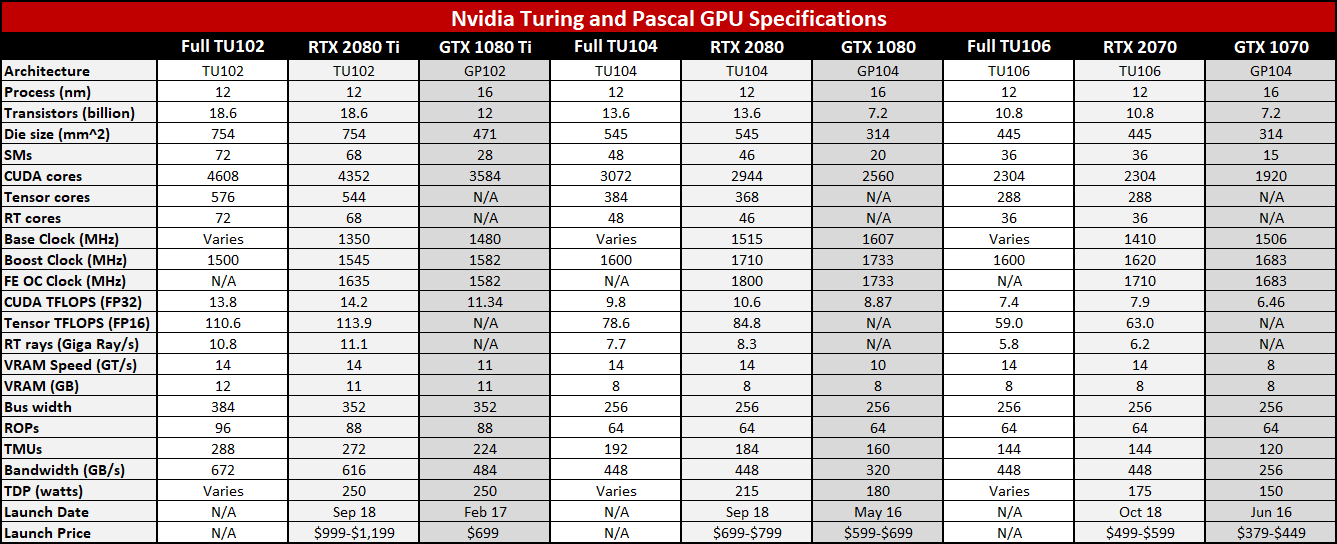
По сравнению с частями предыдущего поколения Pascal архитектура Turing имеет аналогичные тактовые частоты, но увеличивает количество ядер CUDA на 15-20 процентов по всей линии. Это только начало, поскольку Nvidia также добавляет ядра Tensor и ядра RT к изображению, а отдельные SM (потоковые мультипроцессоры) претерпели значительные изменения. Подробнее об этом через минуту.
Еще одно большое изменение заключается в том, что Nvidia одновременно запускает три совершенно разных графических процессора для сегмента высокого класса и энтузиастов. Ранее 1070/1080 и 970/980 были построены из одного и того же кристалла, причем меньшая часть использовала частично отключенную версию. В 2080 и 2080 Ti все еще используются заготовленные матрицы, но 2070 получает отдельный и полный графический процессор TU106. Это также оставляет место для будущих промежуточных графических процессоров, таких как 2070 Ti и Titan RTX, естественно.
Чистая пропускная способность памяти также значительно улучшилась благодаря GDDR6. В 2080 Ti наблюдается наименьшее улучшение — 27 процентов, поскольку в 1080 Ti уже используется 11 GT / s GDDR5X. В эталонном 1080 используется 10 GT / s GDDR5X (в некоторых более поздних пользовательских моделях используется 11 GT / s VRAM), поэтому RTX 2080 имеет пропускную способность на 40 процентов больше. Потенциальный победитель — RTX 2070, который получает существенное увеличение пропускной способности на 75 процентов.
Но пропускная способность и теоретическая производительность являются лишь частью уравнения. Давайте углубимся в глубины и поговорим о низкоуровневых деталях графического процессора, интерфейса памяти и других аспектах архитектуры Тьюринга.
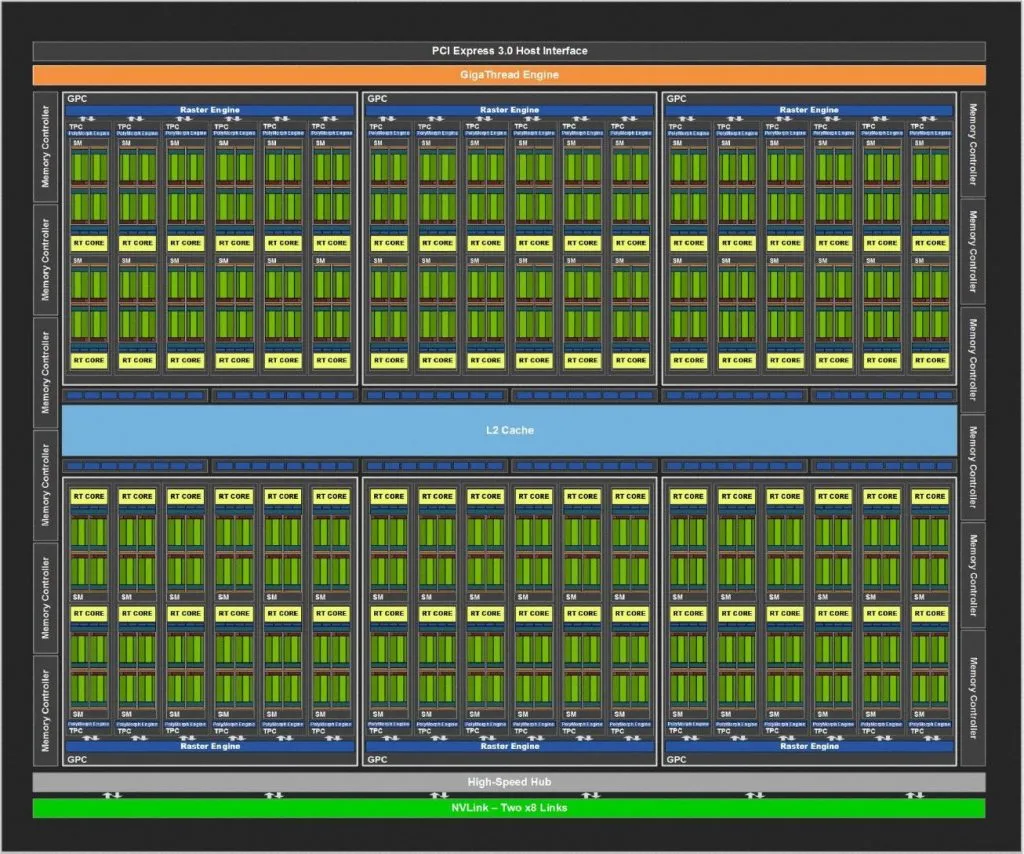
Блок схема тьюринга TU102 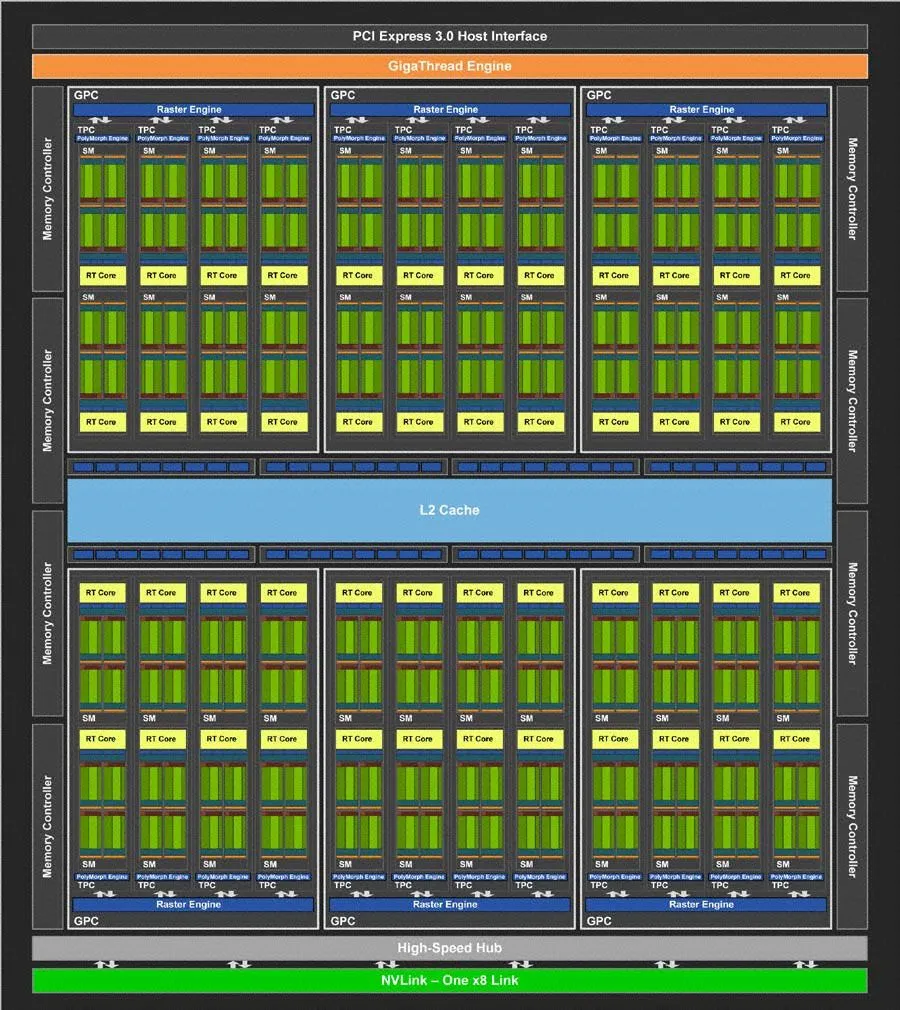
Блок схема тьюринга TU104 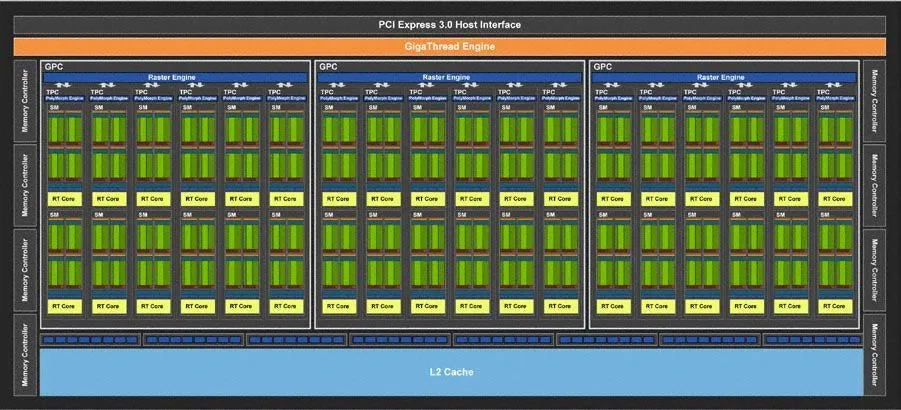
Блок схема тьюринга TU106
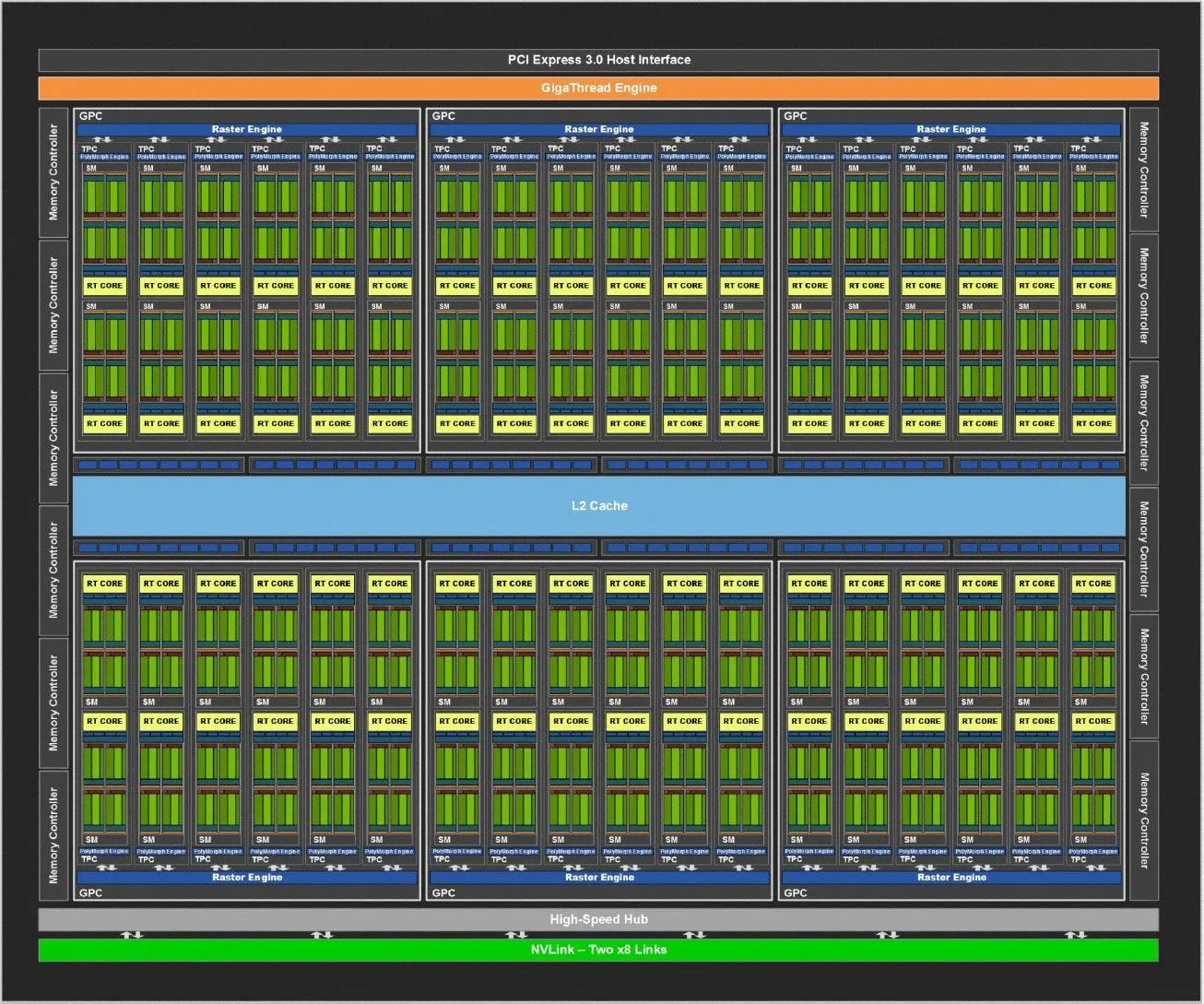
Архитектура Тьюринга: ядро графического процессора
Выше приведена полная блок-схема архитектур Тьюринга TU102 / TU104 / TU106. TU102 состоит из шести GPC (кластеров обработки графики), каждый из которых содержит шесть TPC (кластеров обработки текстур), механизм PolyMorph и выделенный механизм растеризации. Каждый TPC, в свою очередь, связан с двумя SM (потоковыми мультипроцессорами). Это достаточно аббревиатур, чтобы начать нас?
Наряду с GPC, на высоком уровне TU102 включает в себя 12 32-битных контроллеров памяти GDDR6 (всего 384-бит), которые можно отключить независимо. Контроллеры памяти также содержат ROP (выходы рендеринга), поэтому RTX 2080 Ti с 11 контроллерами памяти также имеет 88 ROP.
Хост-интерфейс PCIe 3.0 и другие элементы также находятся за пределами GPC. Обратите внимание, что вышеприведенные диаграммы также не должны восприниматься как буквальное представление о том, как микросхемы разложены на кремнии, а являются просто обзором высокого уровня.
Интересно, что GPC не одинаковы для всех графических процессоров архитектуры Тьюринга. TU104 также имеет шесть GPC, но каждый GPC в TU104 имеет восемь SM, где GPC TU102 и TU106 имеют 12 SM. Однако оба TU104 и TU106 имеют восемь 32-разрядных контроллеров памяти (всего 256-разрядное) вместе с различными другими функциональными блоками.
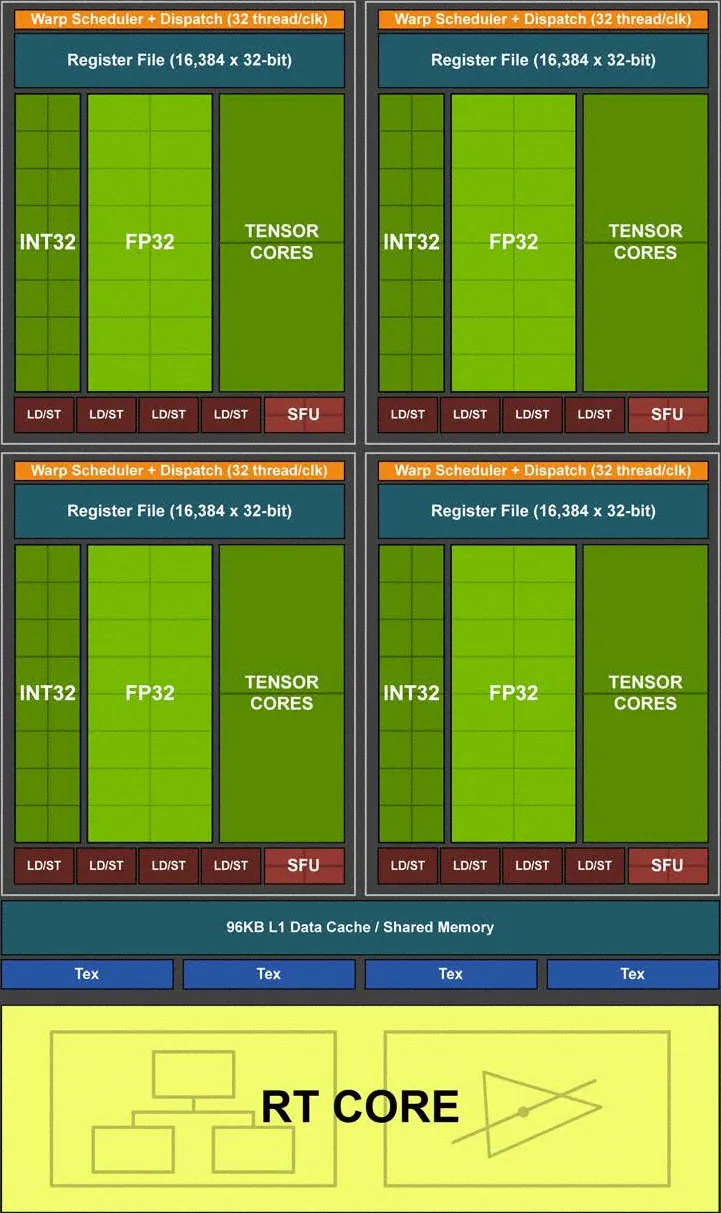
В основе каждого графического процессора лежит фундаментальный строительный блок. Nvidia называет это потоковым мультипроцессором (SM), в то время как AMD называет его вычислительным модулем (CU), но, хотя конкретные реализации различаются, каждый GPU обычно имеет много кластеров SM.
SM архитектуры Turing содержат планировщики, графические ядра, кэш L1 / L2, модули текстурирования и многое другое. Nvidia кардинально изменила архитектуру Turing SM по сравнению с предыдущими архитектурами Pascal и Maxwell, поэтому есть, что рассказать. Давайте начнем с вершины.
Во-первых, число ядер CUDA на SM теперь составляет 64 вместо 128 в Pascal. За последнее десятилетие Nvidia выросла примерно с 32 до 192 ядер CUDA на SM, но Nvidia говорит, что с другими архитектурными изменениями 64 ядра теперь более эффективны. ,
Архитектура Тьюринга также добавляет встроенную поддержку FP16 «быстрой упаковки» в ядра CUDA, что ранее наблюдалось в GP100 и GV100. Производительность для рабочих нагрузок FP16 вдвое выше, чем для ядер FP32, хотя в играх преимущественно используется FP32. На приведенной выше блок-схеме SM не показаны ядра FP64 CUDA, которые отделены от ядер FP32. Для обеспечения совместимости имеется два ядра FP64 на SM, поэтому производительность FP64 составляет 1/32 производительности FP32. (Volta GV100 и Pascal GP100 поддерживают половинную скорость FP64, что полезно во многих суперкомпьютерных рабочих нагрузках.)
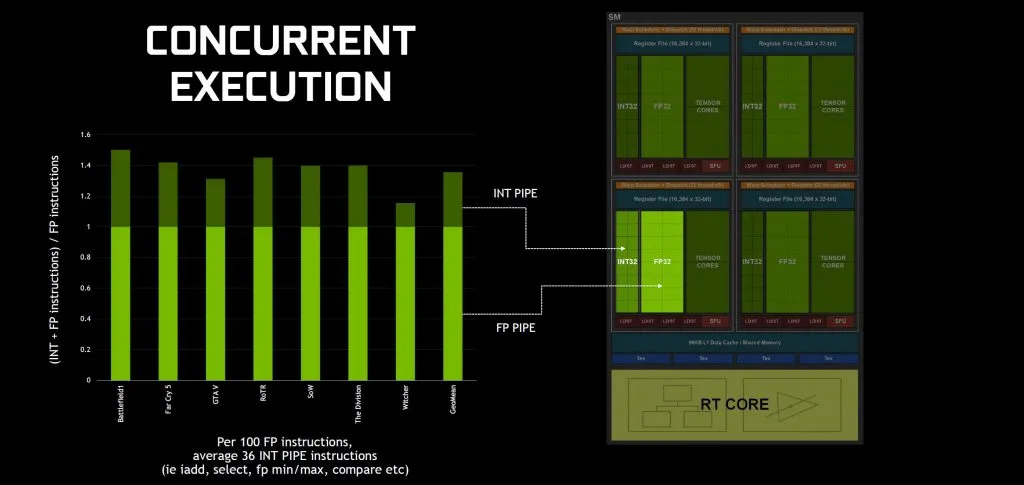
Новым для архитектуры Тьюринга является выделенный целочисленный конвейер, который может работать одновременно с ядрами с плавающей запятой. В то время как графические приложения преимущественно используют вычисления FP, Nvidia профилировала большое количество игр и других приложений и сказала, что обычно есть 35 (или 36, в зависимости от того, к какому документу Nvidia вы обращаетесь) целых инструкций для каждых 100 инструкций FP.
На предыдущих архитектурах ядрам FP приходилось останавливать свою работу, пока графический процессор обрабатывал инструкции INT, но теперь планировщик может отправлять оба на независимые пути. Это обеспечивает теоретическое немедленное улучшение производительности на 35 процентов на ядро.
Это делает ядра GPU в Turing более похожими на современные архитектуры ЦП, и планировщик может отправлять две инструкции за такт. Эти инструкции могут быть также для ядер RT и ядер Tensor.

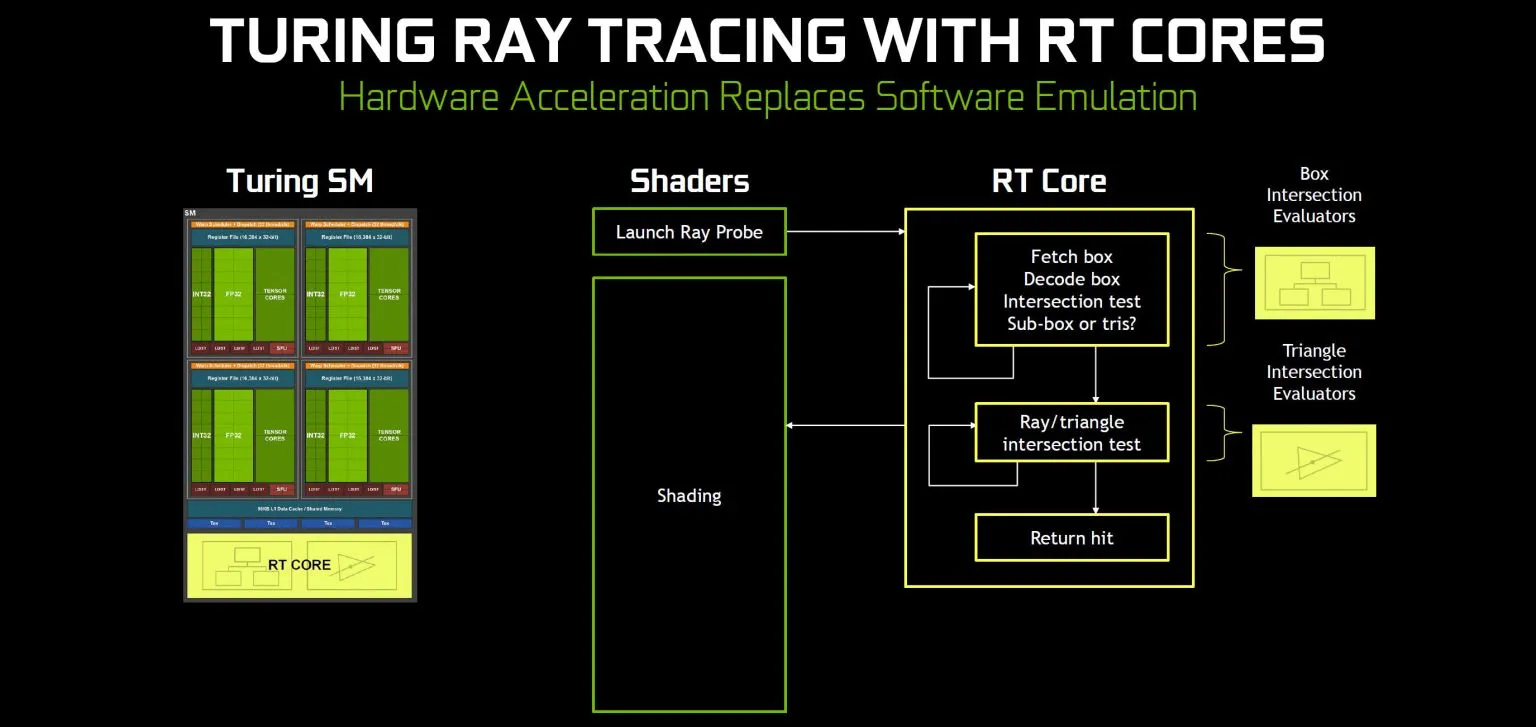
Архитектура Тьюринга: трассировка лучей с ядрами RT
Большинство из вышеперечисленных элементов присутствовали в предыдущих архитектурах графических процессоров Nvidia. Архитектура Тьюринга предоставляет две новые возможности, начиная с ядер RT для трассировки лучей. Я рассмотрел трассировку лучей более подробно в другом месте, так что это сжатая версия, ориентированная на архитектуру.
Каждый SM Turing теперь добавляет одно ядро RT. Nvidia не предоставляет точного числа производительности, поскольку алгоритм BVH с трассировкой лучей не является детерминированным, то есть он не всегда выполняется в одно и то же время. Nvidia говорит, что ядра RT делают «> 10 гигабит в секунду» (GR / s) в GeForce RTX 2080 Ti, и что для каждого GR / s требуется около 10 TFLOPS вычислений. Возвращаясь к этому количеству тактовых частот и ядер RT, я оценил «точную» производительность GR / s для различных графических процессоров Turing в приведенной выше таблице спецификаций.
Важно отметить, что эти RT TFLOPS не являются TFLOPS общего назначения, а представляют собой специальные операции, предназначенные для ускорения вычислений с трассировкой лучей. Ядра RT вычисляют пересечения треугольника луча (где луч попадает в многоугольник), а также обход BVH. Этот второй бит требует более подробного объяснения.
BVH расшифровывается как «иерархия ограничивающих объемов» и представляет собой метод оптимизации расчетов пересечений. Вместо проверки лучей на полигоны объекты инкапсулируются большими простыми объемами. Если луч не пересекает большой объем, нет необходимости в дополнительных усилиях для проверки объекта. И наоборот, если луч пересекает ограничивающий объем, то проверяется следующий уровень иерархии, причем каждый уровень становится более подробным.
Все вычисления BVH могут быть выполнены с использованием шейдерных ядер, но Nvidia говорит, что для каждого луча требуется тысячи шейдерных вычислений, в течение которых ядра CUDA не могут работать с другими компонентами. Ядра RT разгружают все это и работают независимо с ядрами CUDA, поэтому в архитектуре Turing, включающей трассировку лучей, не будет полностью снижена производительность.
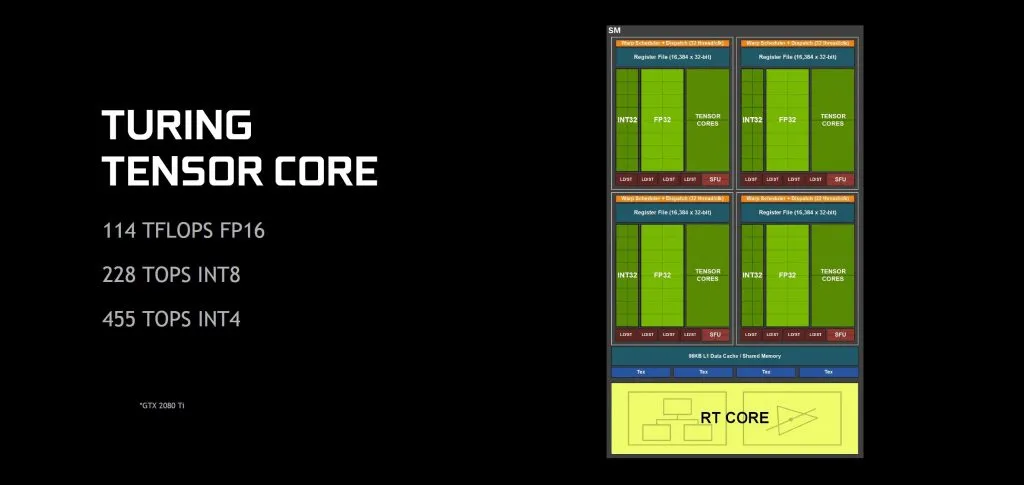
Последняя важная архитектурная особенность Тьюринга — включение ядер Tensor. Обычно используемые для машинного обучения, вы можете удивиться, почему они даже полезны для игр. У меня будет отдельная статья, в которой мы углубимся в аспекты машинного обучения Тьюринга, но вкратце у меня есть большой потенциал.
Nvidia работала с Microsoft над созданием API-интерфейсов DirectML и Windows ML (DirectX Machine Learning), так что это что-то с широкой отраслевой поддержкой. Будущие игры могут использовать машинное обучение для улучшения искусственного интеллекта в играх, улучшения голосовых интерфейсов и улучшения качества изображения. Однако это все долгосрочные цели, особенно если в течение следующих пяти и более лет у большой установленной базы игроков не будет доступных ядер Tensor. В ближайшем будущем эти ядра могут быть использованы более практичным образом.
Nvidia продемонстрировала несколько примеров улучшенного качества масштабирования изображения, где машинное обучение, которое было обучено на миллионах изображений, может привести к лучшему результату с меньшей блочностью и другими артефактами. Представьте себе рендеринг игры с разрешением 1080p с высокой частотой кадров, а затем использование ядер Tensor для повышения качества до псевдо-4k без огромного снижения производительности, которое мы в настоящее время испытываем. Это не обязательно было бы идеально, но внезапно мысль о 4k дисплеях, работающих на 144 Гц с «нативным» контентом 4k, не настолько надуманна.
Ядра Tensor также необходимы для обработки обученного AI алгоритма шумоподавления для трассировки лучей. Пока ядра Tensor работают, остальные графические процессоры в основном не работают, поэтому, в отличие от ядер RT и конвейеров INT / FP, ядра Tensor на самом деле не работают одновременно. Тем не менее, Nvidia предполагает, что DLSS и шумоподавление могут работать только с 20 процентами общего времени кадра.
На аппаратном уровне ядра Tensor архитектуры Turing также добавляют несколько новых приемов по сравнению с таковыми в Volta. В частности, встроенная поддержка рабочих нагрузок INT8 и INT4 позволяет потенциально удвоить или увеличить производительность вычислений в два или четыре раза по сравнению с гибридными моделями FP16 / FP32. Они могут быть не сразу применимы к графическим рабочим нагрузкам, которые более восприимчивы к квантованию, но исследования альтернативных алгоритмов машинного обучения продолжаются.

RTX-OPS, новый показатель производительности
Со всеми изменениями в архитектуре Тьюринга сравнение производительности разных поколений графических процессоров стало намного сложнее. Для существующих игр и рабочих нагрузок, которые не используют новые функции, старая фигура FP32 TFLOPS может все еще быть в порядке, но суперскалярный дизайн (то есть способность отправлять несколько одновременных инструкций) запутывает даже эти цифры. Чтобы помочь в сравнении, Nvidia разработала новую метрику производительности, RTX-OPS.
Очевидно, это будет в пользу графических процессоров RTX, но общая идея не так уж и плоха. В современной игре, в которой полностью реализованы эффекты трассировки лучей с помощью DLSS и шумоподавления, на приведенном выше слайде показано распределение средней рабочей нагрузки. 80 процентов времени тратится на шейдинг FP32 (то, что в настоящее время делают игры), причем 35 процентов этого времени также выполняют параллельную работу шейдинга INT32. В то же время вычисления трассировки лучей используют еще 40 процентов времени, а окончательный результат обрабатывается ядрами Tensor с последними 20 процентами.
С этой формулой GeForce RTX 2080 Ti FE в итоге получает 78 RTX-OPS, как показано. Как сравнить GTX 1080 Ti? В нем отсутствуют ядра Tensor и ядра RT, и он не может выполнять одновременные вычисления INT32 + FP32, поэтому все используют базовую фигуру TFLOPS и просто используют другой фрагмент общего круга. Другими словами, GTX 1080 Ti имеет RTX-OPS, равный его значению TFLOPS 11,3.
Означает ли это, что RTX 2080 Ti почти в семь раз быстрее, чем 1080 Ti? Не совсем, но в будущих рабочих нагрузках, использующих трассировку лучей и код машинного обучения, предыдущие архитектуры просто не смогут конкурировать.
Архитектура Тьюринга: GDDR6 и улучшенный кэш L1 / L2
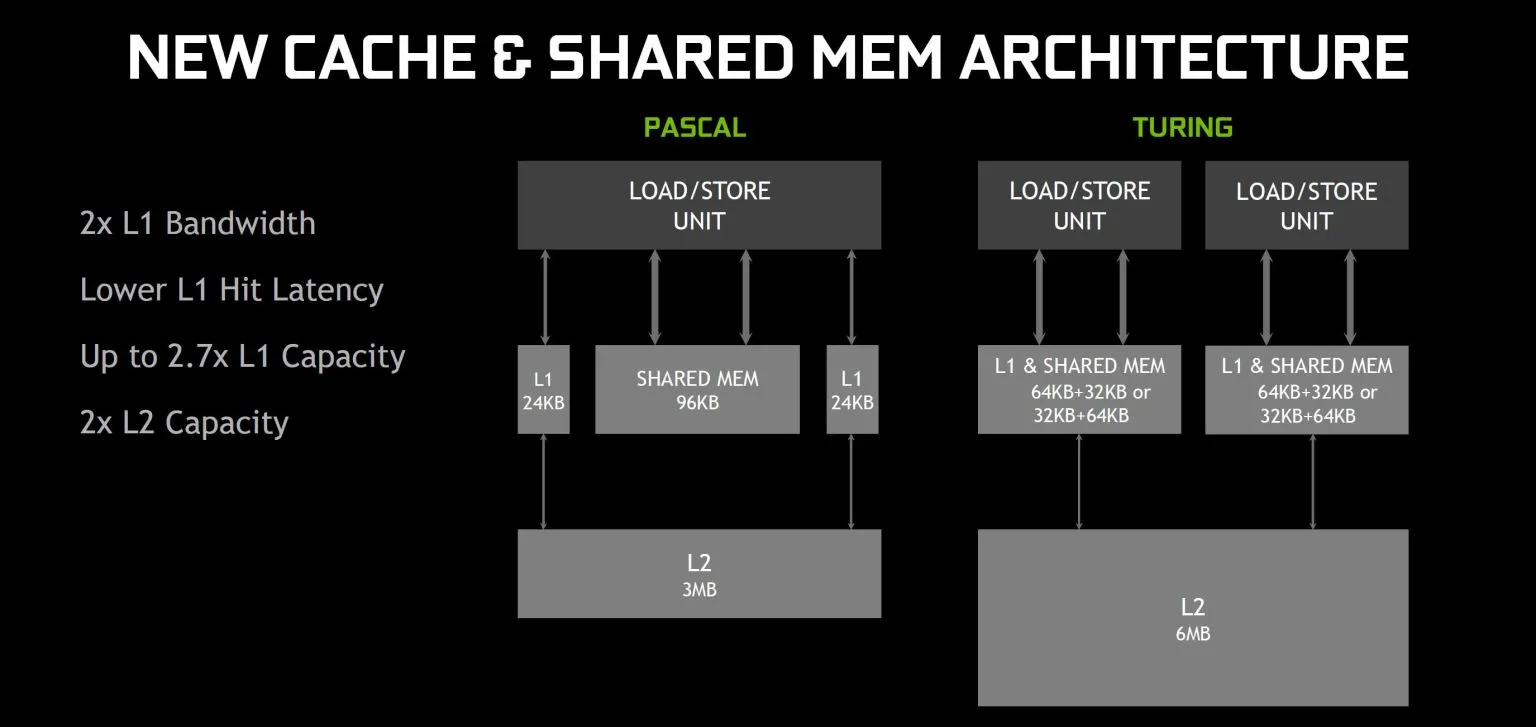
Улучшение общей производительности графического процессора — это замечательно, но более быстрые графические процессоры также требуют большей пропускной способности памяти. Чтобы обеспечить загрузку графических процессоров данными, Nvidia переместилась в память GDDR6 и переработала подсистему кэша и памяти в архитектуре Turing. Пропускная способность кэша L1 удваивается, и теперь кэш L1 может работать как с общей памятью L1 и 64 КБ, так и с общей памятью L1 и 32 КБ 64 КБ. Это потенциально увеличивает размер кэша L1 на 167 процентов по сравнению с Pascal. Размер кэша L2 также был удвоен, и Nvidia заявляет, что кэш L2 также обеспечивает «значительно более высокую пропускную способность».
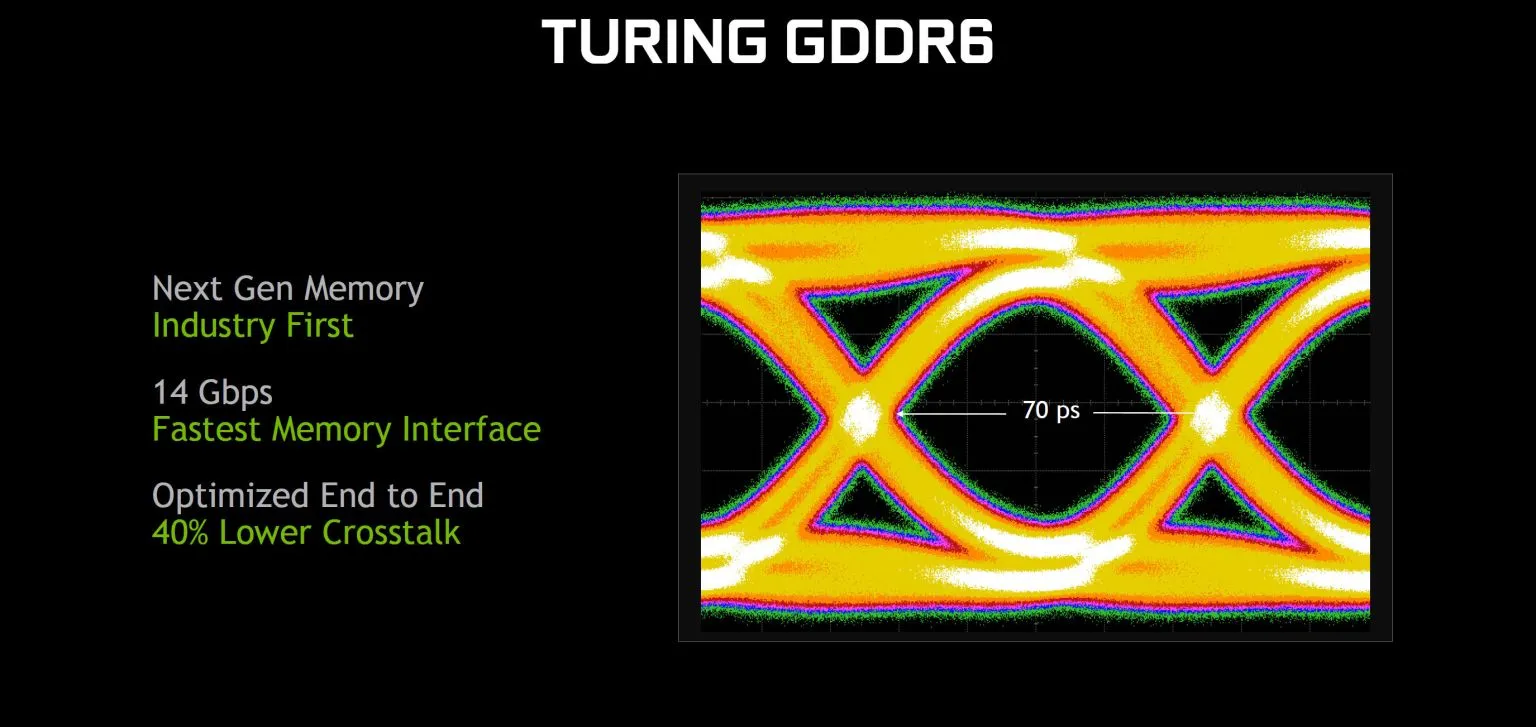
Помогут улучшенные тактовые частоты GDDR6 по сравнению с GDDR5 и GDDR5X, но Тьюринг на этом не останавливается. Мы знаем, что у Паскаля уже было несколько доступных методов сжатия памяти без потерь, и архитектура Тьюринга продолжает улучшаться в этой области. Nvidia не предоставляет конкретных сведений о том, что изменилось, но более крупные кэши и улучшенное сжатие увеличивают эффективную пропускную способность на 20-35 процентов по сравнению с графическими процессорами Pascal.
В совокупности GeForce RTX 2080 Ti имеет в среднем на 50 процентов более эффективную полосу пропускания, чем GTX 1080 Ti, хотя скорость памяти только на 27 процентов выше. RTX 2080 и 2070 должны показать еще большие улучшения, поскольку тактовые частоты памяти увеличились на 40 и 75 процентов соответственно.






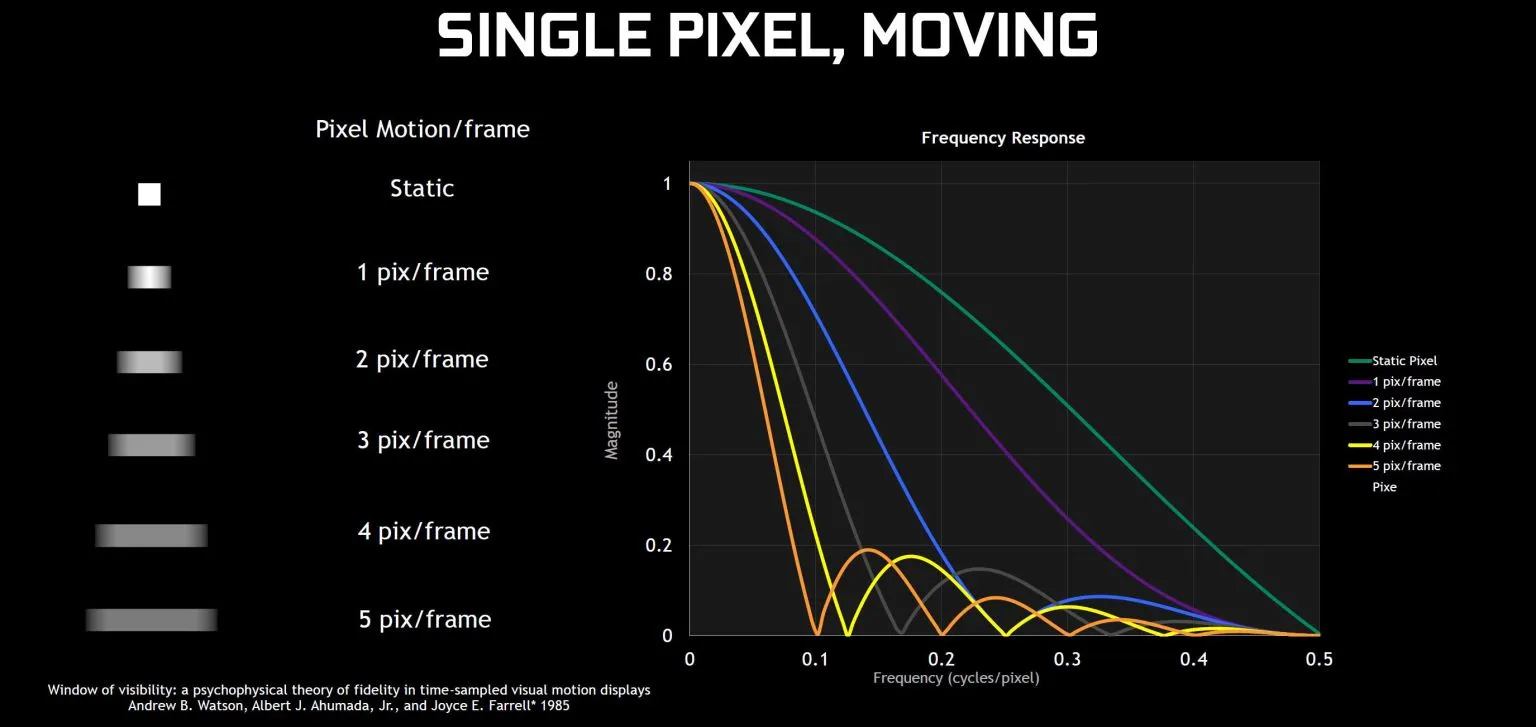
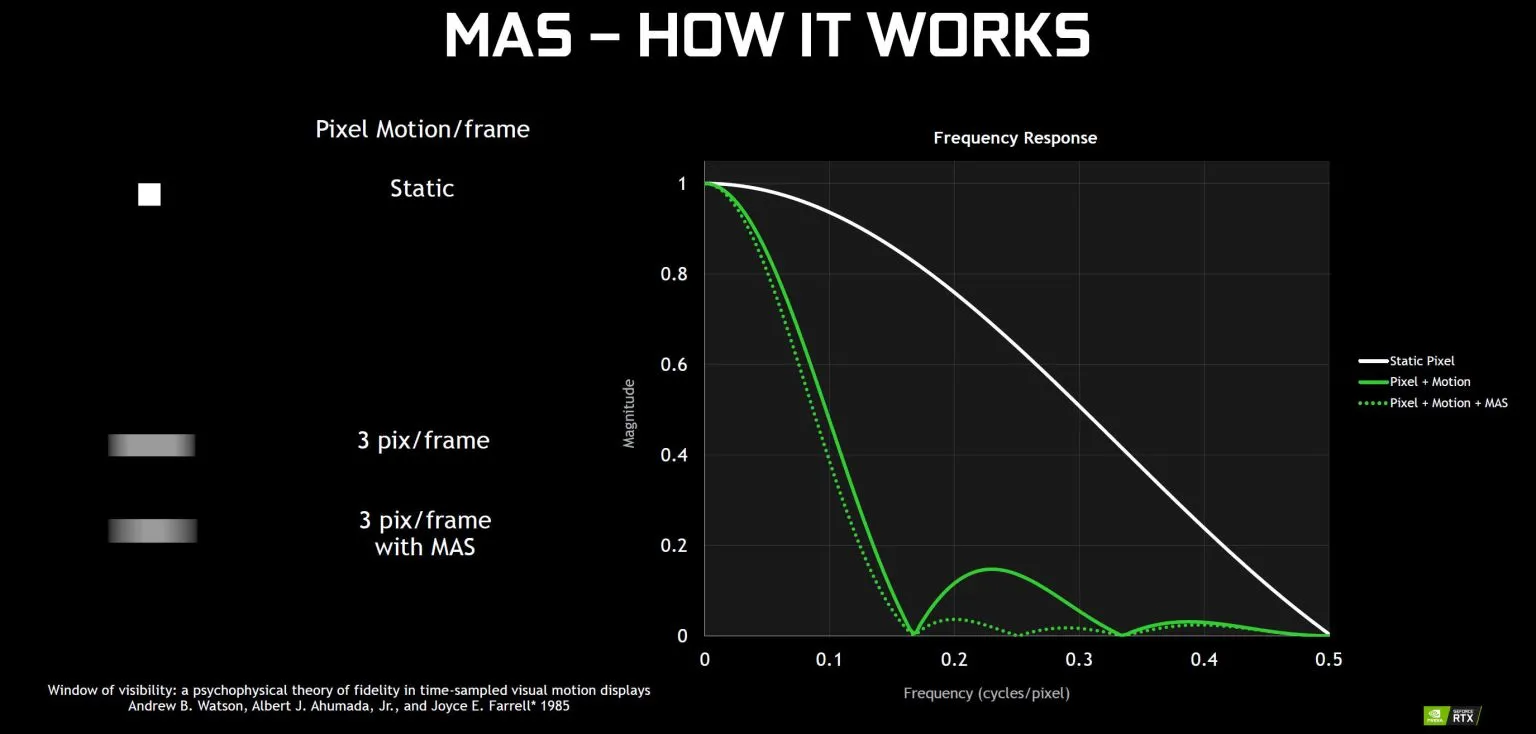

Архитектура Тьюринга: еще больше улучшений
В Тьюринге столько нового, что трудно сказать, насколько важен какой-либо один аспект в долгосрочной перспективе. Архитектуры Pascal и Maxwell также имеют некоторые новые функции — кто-нибудь помнит VXAO, Voxel Ambient Occlusion, который, насколько мне известно, использовался только в двух играх (Rise of the Tomb Raider и Final Fantasy XV)? Возможно, эти другие функции тоже будут полезны, но я собираю их все вместе в галерее выше и в этом коротком описании.
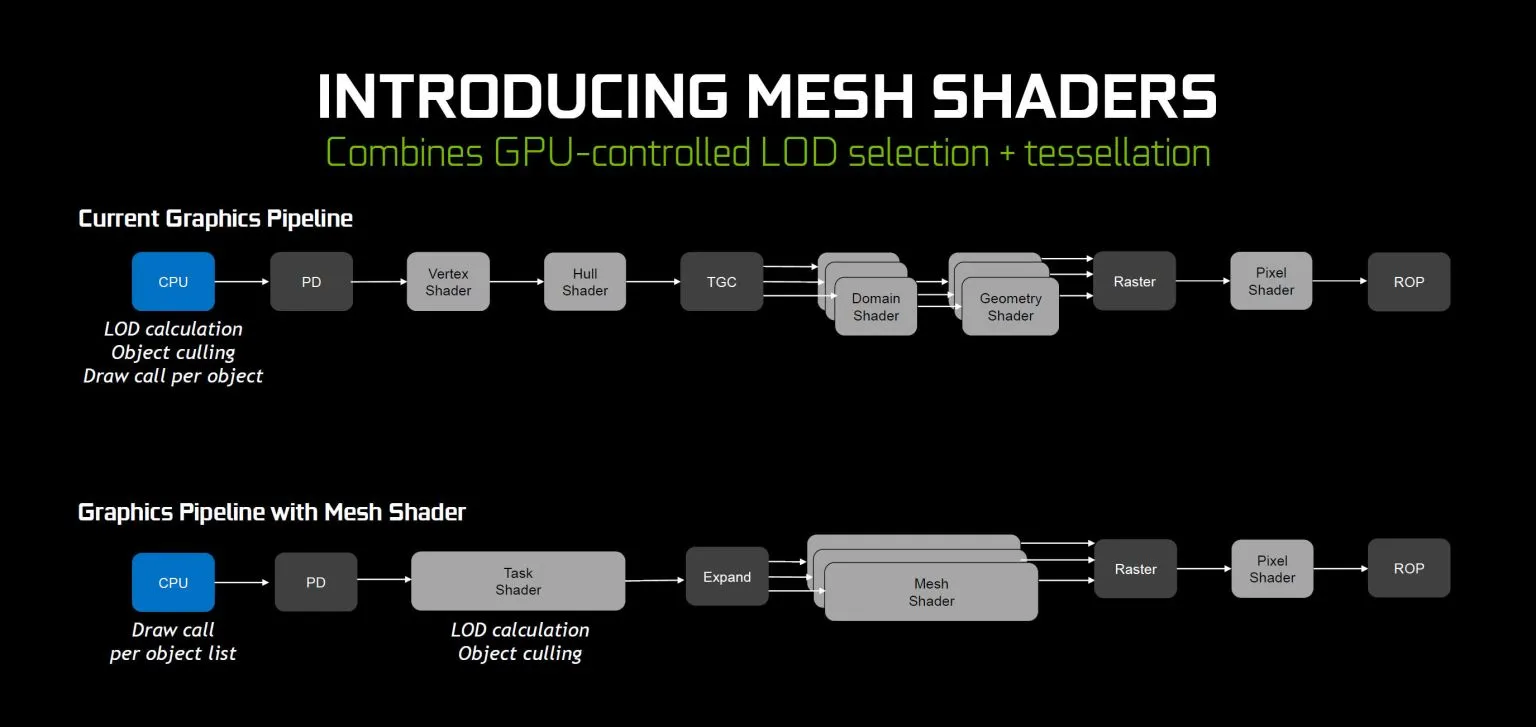
Сетчатые шейдеры — это следующая итерация вершинных, геометрических и тесселяционных шейдеров. Основная идея здесь состоит в том, чтобы перенести расчеты LOD (уровня детализации) из ЦП в графический процессор. Это может улучшить производительность на несколько порядков, и Nvidia продемонстрировала демонстрацию корабля, летящего через массивное поле астероидов с помощью сетчатых шейдеров, позволяющих в реальном времени использовать «триллионы» полигонов. Суть в том, что масштабирование LOD сводит это число к более управляемому, в миллионах, а не в триллионах. В настоящее время сетевые шейдеры будут расширением существующих графических API, поэтому они вряд ли будут широко использоваться до тех пор, пока не будут напрямую интегрированы в API DIrectX / Vulkan, но демонстрация выглядела очень круто.
Шейдинг с переменной скоростью (VRS) — следующая новая функция, которая позволяет играм использовать больше шейдеров там, где это необходимо, и меньше шейдеров, где это не важно. Цель состоит в том, чтобы обеспечить эквивалентное качество изображения с лучшей производительностью, и Nvidia предложила увеличить производительность на 15 процентов. VRS также можно использовать несколькими способами, например, MAS (адаптивное затенение движения), где быстро движущимся объектам не требуется столько деталей (потому что они в конечном итоге становятся размытыми), и CAS (адаптивное затенение контента), где больше усилий затрачивается на сложные Поверхности, как автомобиль, в игре на вождение, и на простых поверхностях, таких как дорога, в той же игре используется меньше усилий.
Nvidia показала модифицированную сборку Wolfenstein II, работающую с CAS, и возможность включения / выключения этой функции. Не тратя больше времени на подсчет пикселей, я могу сказать, что не было сразу видимой разницы между этими двумя режимами, но CAS немного улучшил производительность. Еще увидим, увидим ли мы публичный патч к игре или нет, и опять же, это вряд ли найдет широкое применение.
Наконец, Nvidia кратко обсудила еще две функции в архитектуре Тьюринга: Multi-View Rendering (MVR), улучшенную версию одновременной мульти-проекции (SMP), которая уже была функцией в Pascal, и Texture Space Shading (TSS). В тех случаях, когда SMP в основном сосредоточен на двух видах и приложениях VR, MVP может выполнять четыре вида за проход и удаляет некоторые атрибуты, зависящие от вида. Это должно способствовать дальнейшему повышению производительности в приложениях VR, особенно с некоторыми новыми гарнитурами VR, которые имеют более широкое поле зрения.
Тем временем TSS имеет еще меньше смысла для тех из нас, кто не пишет игровые движки. Nvidia заявляет, что может позволить разработчикам использовать избыточность пространственного и временного рендеринга, эффективно уменьшая объем работы шейдера, который необходимо выполнить. В техническом описании архитектуры Тьюринга есть несколько страниц, описывающих варианты использования TSS, но, как и в случае с предыдущими технологиями, такими как SMP и VXAO, еще неизвестно, сколько разработчиков будет использовать эту функцию.
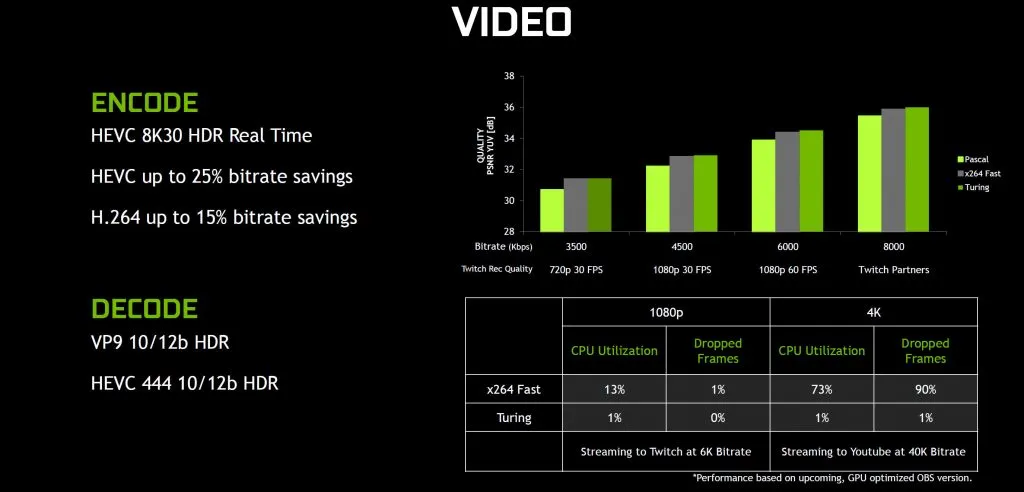
Архитектура Тьюринга: улучшенный NVENC для видео
Помимо улучшения графического процессора и памяти, Nvidia также работала над улучшением NVENC, аппаратного обеспечения, используемого для кодирования / декодирования видео. Графические процессоры Pascal обеспечивают хорошую производительность, но качество получаемых видео не всегда было таким же хорошим, как даже профиль x264 Fast, работающий на процессоре. С Turing Nvidia заявляет, что обеспечивает такое же или лучшее качество, чем x264 Fast, практически без нагрузки на процессор.
Если вы используете потоковую передачу с разрешением 1080p, это не будет иметь большого значения, поскольку Pascal прекрасно справится с этим разрешением, а хороший процессор сможет выполнять быстрое кодирование x264 с небольшими накладными расходами. Перемещение до 4k и более высоких битрейтов — это другой вопрос, с резким увеличением загрузки процессора и большим количеством пропущенных кадров. Turing стремится обеспечить 4K-кодирование практически без влияния на процессор.
Помимо использования потоковой передачи, архитектура Turing также добавляет поддержку кодирования HEVC 8k30 HEVC и может также обеспечить Pascal эквивалентное качество при 15-25% более низких битрейтах для контента HEVC и H.264. Для декодирования Turing добавляет поддержку HDR-контента VP9 10 / 12b и HEVC 444 10 / 12b HDR.

Архитектура Тьюринга: изготовлена с использованием TSMC 12nm FinFET
Развитие архитектуры Тьюринга во многом благодаря усовершенствованиям производственных технологий. Графические процессоры Тьюринга будут производиться с использованием 12-нм процесса TSFC FinFET. В то время как TSMC 12-нм FinFET является скорее усовершенствованием и настройкой существующих 16-нм, а не значительным сокращением размеров элементов, оптимизация технологии процесса за последние два года должна помочь улучшить тактовую частоту, плотность чипа и энергопотребление — святая троица быстрее, меньше и круче работает чипы. На этом этапе процесс 12-нм FinFET в TSMC также является зрелым, с хорошим выходом, что позволяет Nvidia создавать такие большие графические процессоры.
Даже с улучшениями процесса TU102, TU104 и TU106 все очень большие. TU104 в качестве примера лишь немного меньше, чем GP102, используемый в GTX 1080 Ti. Еще более убедительно доказывает тот факт, что 12-нм является больше маркетингом, чем фактическим сжатием, GP102 имеет 12 миллиардов транзисторов по сравнению с 10,8 миллиардами транзисторов TU106. Это на 11 процентов больше транзисторов в GP102, а размер кристалла на восемь процентов больше.
Есть надежда на будущие улучшения скорее раньше, чем позже. TSMC уже близка к полному производству для своего 7-нм процесса, а графические процессоры AMD Vega 7nm Radeon Instinct должны быть выпущены к концу 2018 года. Если TSMC 7nm работает хорошо, мы можем увидеть сокращение Тьюринга к концу 2019 года. Возможно, это произойдет называться Ampere, может быть это будет что-то еще. Мало того, что 7nm снизит размеры до более управляемых уровней, но Nvidia может удвоить ядро RT или другие функции.

Архитектура Nvidia Turing меняет правила игры
Со всем новым в архитектуре Тьюринга легко понять, почему Nvidia называет это самым большим скачком в графических архитектурах, которые когда-либо создавала компания. Трассировка лучей в реальном времени или что-то подобное всегда было мечтой геймеров. Эта мечта прыгнула на 5-10 лет ближе.
Наши графические чипы прошли долгий путь за последние 30 лет, включая такие вехи, как 3dfx Voodoo как первая массовая потребительская карта, способная создавать высокопроизводительную 3D-графику, GeForce 256 как первый графический процессор с ускорением процесса преобразования и освещения, AMD Radeon 9700 Pro — первый полностью программируемый графический процессор DirectX 9. Архитектура Nvidia Turing выглядит столь же значительным изменением по сравнению со своими предшественниками, как и любой из этих продуктов.
Как и все перемены, это не обязательно будет хорошим и чистым разрывом со старым и началом чего-то нового. Какая бы крутая ни была трассировка лучей в реальном времени, она требует нового оборудования. Это общеизвестная проблема курицы и яйца, когда программное обеспечение не будет поддерживать новую функцию без аппаратного обеспечения, но создание аппаратного обеспечения для ускорения чего-то, что в настоящее время не используется, является большой инвестицией. Nvidia инвестировала средства в RTX и его архитектуру Тьюринга, и только время покажет, окупится ли это.
В течение, по крайней мере, следующих пяти лет мы будем в запутанной ситуации, когда у большинства игроков нет карты, способной выполнять трассировку лучей RTX или DXR с приемлемым уровнем производительности — с машинным обучением или без таковых ядер Tensor, чтобы помочь с понижение шума. Хорошая новость заключается в том, что DXR использует многие структуры данных, уже используемые в Direct3D, поэтому добавить некоторые эффекты трассировки лучей в игру не должно быть слишком сложно. Это хорошая новость, поскольку большинству разработчиков игр необходимо продолжать поддерживать устаревшие продукты и технологии растеризации. Я подозреваю, что гибридный рендеринг будет с нами еще долго.
Как бы ни была крута трассировка лучей, мне также интересно, могут ли возможности машинного обучения в Тьюринге оказаться еще более важными. Глубокое обучение революционизирует различные области, включая науку, медицину, автомобилестроение и многое другое. Я не уверен, что DLSS действительно будет выглядеть так же хорошо, как встроенный рендеринг 4k, но я также могу сказать, что разница между 4k и 1440p во многих играх не так велика, как вы могли бы ожидать. Я осторожно оптимистичен, и тем более в отношении таких вещей, как улучшенный искусственный интеллект, античит и другие потенциальные применения.
Архитектура Тьюринга — это визитная карточка ведущей компании в области графических технологий. Это гораздо больше, чем я ожидал увидеть, когда Volta была запущена в прошлом году для суперкомпьютеров. Также шокирует, как быстро GV100 потерял большую часть своей привлекательности. GeForce RTX 2080 Ti за $ 1199 — это очень много, но это также намного выгоднее, чем Titan Xp по той же цене или Titan V за $ 2999.
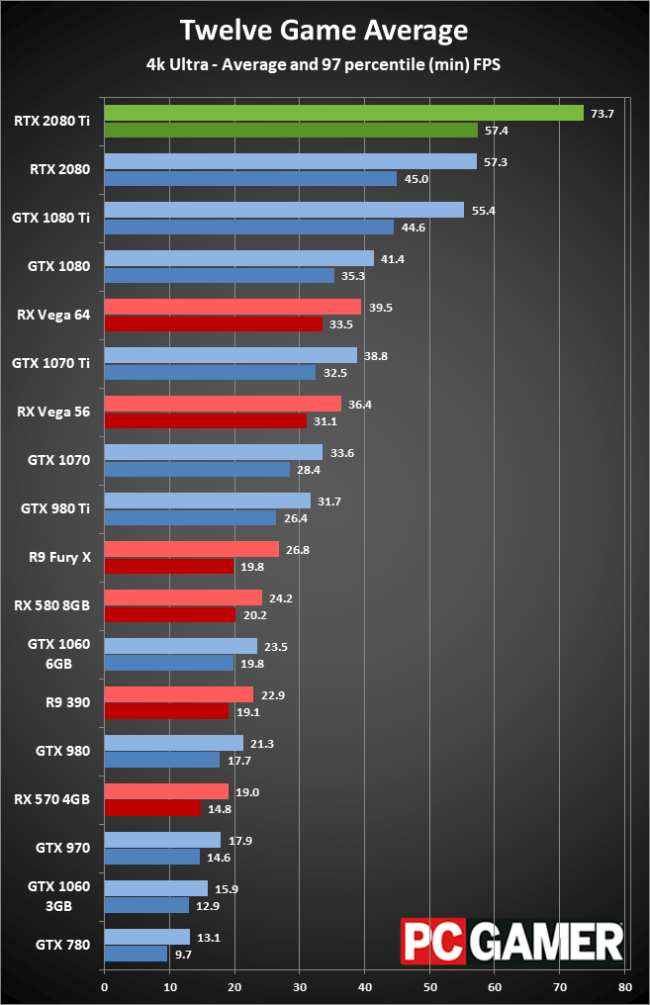
Но пока все теоретические улучшения не делают карты GeForce RTX существенно более быстрыми, чем существующие решения Pascal. Фактически, GTX 1080 Ti и RTX 2080 эффективно связаны в большинстве игр, за исключением того, что плата RTX стоит на 100 долларов дороже. Текущая ситуация напоминает о переходе с DirectX 7 (аппаратное преобразование и освещение) на DX8 / DX9 (полностью программируемые шейдеры), где нам пришлось ждать годы, прежде чем игры должным образом использовали новые функции. Уже в ближайшие шесть месяцев планируется запустить больше игр с трассировкой лучей, чем в ранних играх на DX8, но мы все еще ждем не менее месяца или двух, прежде чем мы увидим, как ядра RT правильно используются в игре.
Комментирование данной статьи отключено, но обратные ссылки открыты.